Some ONNX models have dynamic input/output size:
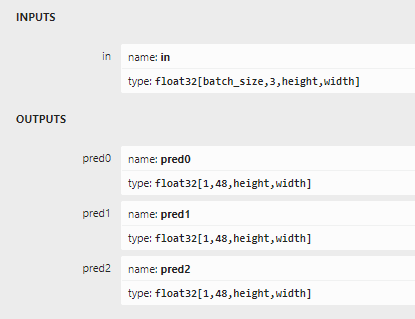
In the above example, onnxruntime will set dimensions of batch_size, height, width to -1.
NOTE: I tested it on onnxruntime v1.13.1 and onnxruntime-win-x64-gpu-1.13.1.zip.
Some tips to avoid runtime errors(these errors often happen, and waste me a lot of time😱):
Ort::Envvariable should be created first when using any other Onnx Runtime functinality.Ort::Envvariable should be alive when inferencing, otherwise it will raise runtime errors.Ort::Envvariable should not be a normal global variable,but it can be a static global variable.Ort::Sessioncan’t be copied.- When you use GPU CUDA inferencing, if you haven’t install proper CUDA and cuDNN, it will fail.
- For Onnx Runtime 1.13, use CUDA 11.6+ and cuDNN 8.6.0+ for Windows
- Official ONNX Runtime GPU packages now require CUDA version >=11.6 instead of 11.4.
- use
nvcc --versionto check CUDA version - check
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\include\cudnn_version.hto find its version.
- use
- Copy
C:\Program Files\NVIDIA Corporation\Nsight Systems 2022.4.2\host-windows-x64\zlib.dlltoC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin\zlibwapi.dll
We should Specify its shape when creating input tensors, like this:
Ort::Value tensor = Ort::Value::CreateTensor<float>(
memory_info,
values.data(),
values.size(),
dims.data(),
dims.size()); // create input tensor object from data values
I’ve test its performance. CUDA is 20+x faster than CPU.
The whole sample code is like this:
#include <assert.h>
#include <vector>
#include <onnxruntime_cxx_api.h>
#include <iostream>
#include "utils.h" // Timer for testing performance
/** Some references
* https://blog.csdn.net/baidu_34595620/article/details/112176278
* https://github.com/microsoft/onnxruntime/blob/9a73c8f448612ca7c5f0635f3f128c3809f63b86/csharp/test/Microsoft.ML.OnnxRuntime.EndToEndTests.Capi/CXX_Api_Sample.cpp#L108
*/
Ort::Session CreateSession()
{
static Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_WARNING, "test"); // must be created first and be alive when inferencing
#ifdef _WIN32
const wchar_t* model_path = L"../models/YoloV5Face.onnx";
#else
const char* model_path = "../models/YoloV5Face.onnx";
#endif
Ort::SessionOptions session_options;
#if defined(DEBUG)
session_options.SetIntraOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
#else
session_options.SetIntraOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
#endif
if (bool use_cuda = true)
{
// https://github.com/microsoft/onnxruntime/issues/10492
// OrtCUDAProviderOptions is a C struct. C programming language doesn't have constructors/destructors.
OrtCUDAProviderOptions cuda_options;
cuda_options.device_id = 0;
// But is zero a valid value for every variable? Not quite. It is not guaranteed. In the other words: does every enum
// type contain zero? The following line can be omitted because EXHAUSTIVE is mapped to zero in onnxruntime_c_api.h.
cuda_options.cudnn_conv_algo_search = OrtCudnnConvAlgoSearchExhaustive;
cuda_options.gpu_mem_limit = static_cast<int>(SIZE_MAX * 1024 * 1024);
cuda_options.arena_extend_strategy = 1;
cuda_options.do_copy_in_default_stream = 1;
cuda_options.default_memory_arena_cfg = nullptr;
session_options.AppendExecutionProvider_CUDA(cuda_options);
// from now on,
// I don't know why TensorRT can't boost performance???
//OrtTensorRTProviderOptions trt_options{};
//trt_options.device_id = 0;
//// TensorRT option trt_max_workspace_size must be a positive integer value. Set it to 1073741824(1GB)
//trt_options.trt_max_workspace_size = 1073741824;
//// TensorRT option trt_max_partition_iterations must be a positive integer value. Set it to 1000
//trt_options.trt_max_partition_iterations = 1000;
//// TensorRT option trt_min_subgraph_size must be a positive integer value. Set it to 1
//trt_options.trt_min_subgraph_size = 1;
//trt_options.trt_fp16_enable = 1;
//trt_options.trt_int8_use_native_calibration_table = 1;
//trt_options.trt_engine_cache_enable = 1;
//trt_options.trt_dump_subgraphs = 1;
//session_options.AppendExecutionProvider_TensorRT(trt_options);
}
// loading models and create session
return Ort::Session(env, model_path, session_options);
}
std::vector<Ort::Value> CreateInput(std::vector<float>& values, const std::vector<int64_t>& dims)
{
Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value tensor = Ort::Value::CreateTensor<float>(
memory_info,
values.data(),
values.size(),
dims.data(),
dims.size()); // create input tensor object from data values
assert(tensor.IsTensor());
std::vector<Ort::Value> ort_inputs;
ort_inputs.emplace_back(std::move(tensor));
return ort_inputs;
}
int main()
{
utils::Timer timer;
Ort::Session session = CreateSession();
// I've already know there is only one input node.
std::vector<int64_t> input0_dims = { 1, 3, 1280, 640 };
std::vector<float> input0_values(input0_dims[1] * input0_dims[2] * input0_dims[3], 0.0);
std::vector<Ort::Value> ort_inputs = CreateInput(input0_values, input0_dims);
std::vector<const char*> input_names = { "in" };
std::vector<const char*> output_names = { "pred0", "pred1", "pred2" };
std::vector<Ort::Value> output_tensors = session.Run(
Ort::RunOptions{ nullptr },
input_names.data(), ort_inputs.data(), ort_inputs.size(),
output_names.data(), output_names.size()); // warm up
// ============================================================
// testing performance
timer.Start();
constexpr int run_count = 20;
for (int i = 0; i < run_count; ++i)
{
output_tensors = session.Run(
Ort::RunOptions{ nullptr },
input_names.data(), ort_inputs.data(), ort_inputs.size(),
output_names.data(), output_names.size());
}
std::cout << "elapsed: " << timer.GetIntervalMilliseconds() / static_cast<double>(run_count) << std::endl;
// ============================================================
// get pointer to output tensor float values
float* floatarr = output_tensors[0].GetTensorMutableData<float>();
float* floatarr1 = output_tensors[1].GetTensorMutableData<float>();
float* floatarr2 = output_tensors[2].GetTensorMutableData<float>();
}
The problem here is I can’t use TensorRT to boost my performance.
I don’t know why. I may solve this issue later on.