EchoMimicV2 Testing Dataset (EMTD) for Halfbody Human| Portrait Animation Series #4

Buiding a dataset is often a tedius but critical task. However, when you can run EchoMimicV2 and understand how the pose inputs work, you may want to have a dataset.
Running EchoMimicV2 on Windows 11 | Portrait Animation Series #1
EchoMimicV2 is an opensource framework for audio driven human portrait animation. Compared to many other solutions…heyulong3d.medium.com
EchoMimicV2 provided a dataset (and some scripts) for evaluating halfbody human animation. However, the process was not very smooth and I spent a couple of hours on troubleshooting the issues within it.
· Step 1: Download yt-dlp
· Step 2: Download EMTD Videos
· Step 3: Slice Dataset
· Step 4: Preprocess Dataset
· References
Step 1: Download yt-dlp
First make sure that terminal is installed.
Install yt-dlp in the terminal on Windows:
winget install yt-dlp.yt-dlp
Restart the terminal to check whetheryt-dlp.exeis installed:
yt-dlp.exe --version # mine: 2025.08.11
Step 2: Download EMTD Videos
Following the official instructions and running the download.py , I encountered this error:
ERROR: [youtube] -BR9P4E7liU: Requested format is not available. Use --list-formats for a list of available formats
It just does not work. After spending time on troubleshooting with ChatGPT and https://github.com/yt-dlp/yt-dlp, this version finally works for me.
# to replace download.py
import os
import subprocess
import pandas as pd
def run(cmd):
return subprocess.run(cmd, capture_output=True, text=True, encoding='utf-8')
def download_youtube_video(video_url, out_dir):
base_cmd = [
"yt-dlp",
"-N", "8", # parallel connections for robustness/speed
"--concurrent-fragments", "8",
"--force-ipv4",
"--no-part",
"--retries", "10",
"--fragment-retries", "15",
"--retry-sleep", "exp=1:30",
"-f", "bv*+ba/b", # best video+audio of ANY container, else best single
"--merge-output-format", "mp4", # remux to mp4 when codecs allow
"-o", os.path.join(out_dir, "%(id)s.%(ext)s"),
video_url,
]
# If some items need login/age/region, uncomment ONE of these:
# base_cmd += ["--cookies-from-browser", "chrome"] # or edge/firefox
# base_cmd += ["--cookies", "cookies.txt"]
r = subprocess.run(base_cmd, capture_output=True, text=True, encoding="utf-8")
if r.returncode == 0:
print(f"OK {video_url}")
return True
# Fallback: force re-encode to mp4 if remux failed or formats mismatched
if "Requested format is not available" in r.stderr or "merge" in r.stderr.lower():
fallback_cmd = [c for c in base_cmd if c not in ["--merge-output-format", "mp4"]]
fallback_cmd += ["--recode-video", "mp4"]
r2 = subprocess.run(fallback_cmd, capture_output=True, text=True, encoding="utf-8")
if r2.returncode == 0:
print(f"OK {video_url}")
return True
# Only if you see 403 or similar, try cookies as a fallback:
err = (r.stderr or "") + (r.stdout or "")
if "403" in err or "fragment 1 not found" in err.lower():
r2 = subprocess.run(
base_cmd[:1] + ["--cookies-from-browser", "edge"] + base_cmd[1:],
capture_output=True, text=True, encoding="utf-8"
)
if r2.returncode == 0:
print(f"OK {video_url}")
return True
print(f"Fail to download {video_url}, error info:\n{r.stderr}")
# Optional: print available formats for this one ID to inspect
fmts = subprocess.run(["yt-dlp", "-F", video_url], capture_output=True, text=True, encoding="utf-8")
print(fmts.stdout or fmts.stderr)
return False
if __name__ == "__main__":
# Make sure you’re using yt-dlp (not old youtube-dl)
# pip install -U yt-dlp
# and have ffmpeg in PATH
df = pd.read_csv("./echomimicv2_benchmark_url+start_timecode+end_timecode.txt")
save_dir = "ori_video_dir"
os.makedirs(save_dir, exist_ok=True)
urls = list(dict.fromkeys(df["URL"])) # keep order, drop dups
ok, bad = 0, []
for u in urls:
if download_youtube_video(u, save_dir):
ok += 1
else:
bad.append(u)
print(f"\nDone. Success: {ok}/{len(urls)}")
if bad:
print("Failed URLs:")
for u in bad:
print(" ", u)
The output was like this:
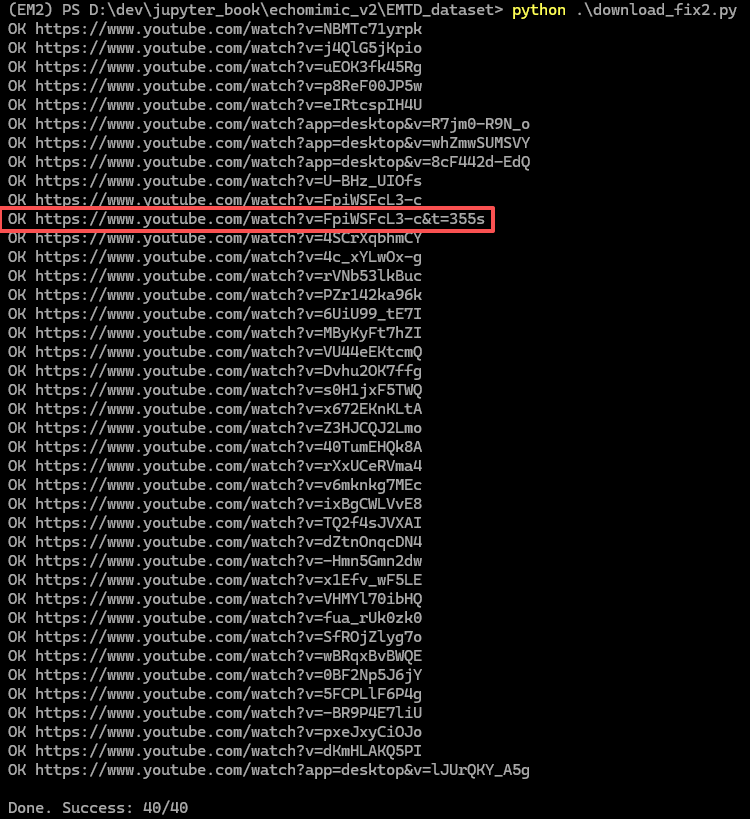
But there were actually 39 videos. Then, I noticed some urls in the echomimicv2_benchmark_url_start_timecode+end_timecode.txt are inconsistent. Moreover, there are some unnecessary tags.

So, I removed them in this file:
URL,Start Timecode,End Timecode
https://www.youtube.com/watch?v=NBMTc71yrpk,00:00:54.596,00:01:01.561
https://www.youtube.com/watch?v=NBMTc71yrpk,00:02:04.207,00:02:11.006
https://www.youtube.com/watch?v=NBMTc71yrpk,00:03:06.103,00:03:13.819
https://www.youtube.com/watch?v=NBMTc71yrpk,00:03:51.231,00:03:56.445
https://www.youtube.com/watch?v=NBMTc71yrpk,00:05:39.047,00:05:43.677
https://www.youtube.com/watch?v=NBMTc71yrpk,00:07:14.851,00:07:22.734
https://www.youtube.com/watch?v=j4QlG5jKpio,00:02:31.777,00:02:41.328
https://www.youtube.com/watch?v=j4QlG5jKpio,00:04:10.750,00:04:31.146
https://www.youtube.com/watch?v=j4QlG5jKpio,00:06:25.135,00:06:38.231
https://www.youtube.com/watch?v=j4QlG5jKpio,00:08:32.554,00:08:39.144
https://www.youtube.com/watch?v=uEOK3fk45Rg,00:02:28.750,00:02:45.625
https://www.youtube.com/watch?v=uEOK3fk45Rg,00:05:36.167,00:05:51.167
https://www.youtube.com/watch?v=uEOK3fk45Rg,00:07:46.833,00:08:00.625
https://www.youtube.com/watch?v=uEOK3fk45Rg,00:09:51.708,00:10:00.250
https://www.youtube.com/watch?v=p8ReF00JP5w,00:02:10.417,00:02:18.583
https://www.youtube.com/watch?v=p8ReF00JP5w,00:05:09.583,00:05:19.708
https://www.youtube.com/watch?v=eIRtcspIH4U,00:04:43.950,00:05:59.025
https://www.youtube.com/watch?v=eIRtcspIH4U,00:07:35.664,00:08:19.916
https://www.youtube.com/watch?v=eIRtcspIH4U,00:10:17.867,00:10:32.924
https://www.youtube.com/watch?v=R7jm0-R9N_o,00:02:39.493,00:02:55.609
https://www.youtube.com/watch?v=R7jm0-R9N_o,00:04:15.088,00:04:41.114
https://www.youtube.com/watch?v=R7jm0-R9N_o,00:06:08.635,00:06:42.035
https://www.youtube.com/watch?v=R7jm0-R9N_o,00:08:08.288,00:08:19.532
https://www.youtube.com/watch?v=R7jm0-R9N_o,00:09:52.659,00:10:10.009
https://www.youtube.com/watch?v=whZmwSUMSVY,00:02:03.832,00:02:17.471
https://www.youtube.com/watch?v=whZmwSUMSVY,00:05:18.610,00:05:29.496
https://www.youtube.com/watch?v=whZmwSUMSVY,00:08:14.577,00:08:50.155
https://www.youtube.com/watch?v=8cF442d-EdQ,00:06:30.720,00:07:25.360
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:00:38.360,00:00:42.880
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:01:21.320,00:01:35.840
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:01:56.920,00:02:00.760
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:04:38.160,00:04:44.440
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:05:12.520,00:05:16.880
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:05:45.680,00:05:51.480
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:06:12.640,00:06:18.880
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:07:00.640,00:07:08.200
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:09:23.480,00:09:27.680
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:09:50.640,00:09:53.920
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:10:17.560,00:10:22.360
https://www.youtube.com/watch?v=U-BHz_UIOfs,00:10:49.880,00:10:58.000
https://www.youtube.com/watch?v=FpiWSFcL3-c,00:07:14.100,00:07:18.938
https://www.youtube.com/watch?v=FpiWSFcL3-c,00:05:17.317,00:05:19.528
https://www.youtube.com/watch?v=4SCrXqbhmCY,00:00:02.336,00:00:05.255
https://www.youtube.com/watch?v=4SCrXqbhmCY,00:00:38.288,00:00:43.293
https://www.youtube.com/watch?v=4SCrXqbhmCY,00:00:58.725,00:01:01.728
https://www.youtube.com/watch?v=4SCrXqbhmCY,00:01:28.964,00:01:35.220
https://www.youtube.com/watch?v=4SCrXqbhmCY,00:01:50.027,00:02:01.079
https://www.youtube.com/watch?v=4SCrXqbhmCY,00:03:05.852,00:03:16.488
https://www.youtube.com/watch?v=4SCrXqbhmCY,00:03:52.482,00:04:00.615
https://www.youtube.com/watch?v=4SCrXqbhmCY,00:05:08.642,00:05:12.270
https://www.youtube.com/watch?v=4SCrXqbhmCY,00:05:32.624,00:05:35.627
https://www.youtube.com/watch?v=4c_xYLwOx-g,00:03:17.739,00:03:22.953
https://www.youtube.com/watch?v=rVNb53lkBuc,00:01:17.867,00:01:28.533
https://www.youtube.com/watch?v=rVNb53lkBuc,00:02:55.500,00:03:00.600
https://www.youtube.com/watch?v=rVNb53lkBuc,00:04:05.767,00:04:15.333
https://www.youtube.com/watch?v=rVNb53lkBuc,00:05:04.900,00:05:09.933
https://www.youtube.com/watch?v=rVNb53lkBuc,00:05:47.833,00:05:53.967
https://www.youtube.com/watch?v=rVNb53lkBuc,00:07:04.933,00:07:11.900
https://www.youtube.com/watch?v=rVNb53lkBuc,00:08:53.767,00:09:16.367
https://www.youtube.com/watch?v=rVNb53lkBuc,00:11:40.333,00:11:45.500
https://www.youtube.com/watch?v=PZr142ka96k,00:00:58.141,00:01:00.477
https://www.youtube.com/watch?v=PZr142ka96k,00:03:11.358,00:03:17.030
https://www.youtube.com/watch?v=6UiU99_tE7I,00:00:05.923,00:00:10.385
https://www.youtube.com/watch?v=6UiU99_tE7I,00:00:48.215,00:00:51.343
https://www.youtube.com/watch?v=6UiU99_tE7I,00:02:36.531,00:02:40.077
https://www.youtube.com/watch?v=6UiU99_tE7I,00:04:08.498,00:04:17.299
https://www.youtube.com/watch?v=MByKyFt7hZI,00:00:11.637,00:00:16.350
https://www.youtube.com/watch?v=MByKyFt7hZI,00:02:46.958,00:03:02.432
https://www.youtube.com/watch?v=MByKyFt7hZI,00:03:54.568,00:03:58.488
https://www.youtube.com/watch?v=VU44eEKtcmQ,00:00:34.117,00:00:39.957
https://www.youtube.com/watch?v=VU44eEKtcmQ,00:01:50.819,00:01:56.616
https://www.youtube.com/watch?v=VU44eEKtcmQ,00:03:14.694,00:03:18.990
https://www.youtube.com/watch?v=Dvhu2OK7ffg,00:01:53.905,00:01:56.992
https://www.youtube.com/watch?v=Dvhu2OK7ffg,00:04:51.333,00:04:58.381
https://www.youtube.com/watch?v=s0H1jxF5TWQ,00:01:55.699,00:01:58.452
https://www.youtube.com/watch?v=x672EKnKLtA,00:00:55.389,00:01:01.895
https://www.youtube.com/watch?v=Z3HJCQJ2Lmo,00:01:36.240,00:01:39.520
https://www.youtube.com/watch?v=40TumEHQk8A,00:01:43.020,00:01:46.690
https://www.youtube.com/watch?v=rXxUCeRVma4,00:02:51.880,00:02:58.887
https://www.youtube.com/watch?v=v6mknkg7MEc,00:03:26.080,00:03:36.000
https://www.youtube.com/watch?v=v6mknkg7MEc,00:06:09.880,00:06:32.120
https://www.youtube.com/watch?v=v6mknkg7MEc,00:09:30.960,00:09:40.240
https://www.youtube.com/watch?v=ixBgCWLVvE8,00:02:38.300,00:03:05.133
https://www.youtube.com/watch?v=ixBgCWLVvE8,00:04:37.033,00:04:43.833
https://www.youtube.com/watch?v=TQ2f4sJVXAI,00:01:22.900,00:01:47.133
https://www.youtube.com/watch?v=dZtnOnqcDN4,00:00:48.067,00:01:12.667
https://www.youtube.com/watch?v=dZtnOnqcDN4,00:04:09.833,00:04:23.867
https://www.youtube.com/watch?v=dZtnOnqcDN4,00:07:25.733,00:07:52.067
https://www.youtube.com/watch?v=dZtnOnqcDN4,00:09:41.000,00:10:02.233
https://www.youtube.com/watch?v=-Hmn5Gmn2dw,00:04:40.208,00:04:49.458
https://www.youtube.com/watch?v=x1Efv_wF5LE,00:05:35.833,00:05:41.733
https://www.youtube.com/watch?v=VHMYl70ibHQ,00:03:41.500,00:04:15.833
https://www.youtube.com/watch?v=fua_rUk0zk0,00:06:47.867,00:07:11.433
https://www.youtube.com/watch?v=SfROjZlyg7o,00:03:26.400,00:03:38.960
https://www.youtube.com/watch?v=SfROjZlyg7o,00:06:22.240,00:06:44.160
https://www.youtube.com/watch?v=wBRqxBvBWQE,00:10:13.208,00:10:32.125
https://www.youtube.com/watch?v=0BF2Np5J6jY,00:02:51.280,00:02:58.920
https://www.youtube.com/watch?v=0BF2Np5J6jY,00:04:57.040,00:05:16.680
https://www.youtube.com/watch?v=0BF2Np5J6jY,00:07:33.400,00:07:43.240
https://www.youtube.com/watch?v=0BF2Np5J6jY,00:09:45.560,00:09:59.680
https://www.youtube.com/watch?v=5FCPLlF6P4g,00:01:46.280,00:01:54.880
https://www.youtube.com/watch?v=5FCPLlF6P4g,00:03:22.200,00:03:41.640
https://www.youtube.com/watch?v=5FCPLlF6P4g,00:05:05.400,00:05:16.160
https://www.youtube.com/watch?v=5FCPLlF6P4g,00:06:52.480,00:07:05.360
https://www.youtube.com/watch?v=-BR9P4E7liU,00:01:52.320,00:02:03.360
https://www.youtube.com/watch?v=-BR9P4E7liU,00:05:05.760,00:05:17.000
https://www.youtube.com/watch?v=pxeJxyCiOJo,00:02:48.320,00:03:08.920
https://www.youtube.com/watch?v=dKmHLAKQ5PI,00:05:55.337,00:06:01.998
https://www.youtube.com/watch?v=lJUrQKY_A5g,00:04:36.208,00:04:50.958
https://www.youtube.com/watch?v=lJUrQKY_A5g,00:08:21.583,00:08:43.042
Run the script again. Now, it looks clean.

Step 3: Slice Dataset
Run the script slice_video.py (not slice.sh ; it is very misleading in the offcial documentation).
import os
import cv2
import subprocess
import pandas as pd
import numpy as np
from tqdm import tqdm
from multiprocessing import Pool
def split_video(info):
input_fp, star_timecode, end_timecode, output_fp = info
try:
if not os.path.exists(os.path.dirname(output_fp)):
os.makedirs(os.path.dirname(output_fp), exist_ok=True)
cap = cv2.VideoCapture(input_fp)
fps = cap.get(cv2.CAP_PROP_FPS)
s_hours, s_minutes, s_seconds = map(float, star_timecode.split(':'))
start_second_timestamp = s_hours*3600+s_minutes*60+s_seconds+1/fps*3
e_hours, e_minutes, e_seconds = map(float, end_timecode.split(':'))
end_second_timestamp = e_hours*3600+e_minutes*60+e_seconds-1/fps*3
command = ['ffmpeg', '-i', input_fp, '-ss', str(start_second_timestamp), '-to', str(end_second_timestamp), output_fp, '-y']
result = subprocess.run(command, capture_output=True, text=True, encoding='utf-8')
if result.returncode == 0:
print('Split {:s} successfully!'.format(output_fp))
else:
print("Fail to split {:s}, error info:\n{:s}".format(output_fp, result.stderr))
except Exception as e:
print(f"error: {e}")
if __name__ == '__main__':
ori_video_dir = "ori_video_dir/"
output_dir = "temp"
df = pd.read_csv("echomimicv2_benchmark_url+start_timecode+end_timecode.txt")
infos = np.array(df).tolist()
input_video_paths = []
star_timecodes = []
end_timecodes = []
output_video_paths = []
times = []
for idx, info in enumerate(infos):
tem_url = info[0]
tem_stime = info[1]
tem_etime = info[2]
tem_video_path = os.path.join(ori_video_dir, tem_url.split('v=')[1]+".mp4")
if os.path.exists(tem_video_path):
input_video_paths.append(tem_video_path)
star_timecodes.append(tem_stime)
end_timecodes.append(tem_etime)
output_video_paths.append(os.path.join(output_dir, "{:03d}_{}.mp4".format(idx, tem_url.split('v=')[1])))
workers = 4
pool = Pool(processes=workers)
for chunks_data in tqdm(pool.imap_unordered(split_video, zip(input_video_paths,star_timecodes,end_timecodes, output_video_paths))):
None
This slices videos based on timestamps. All 110 videos are stored in the temp folder.
Step 4: Preprocess Dataset
Updated the preprocess.py :
import sys
from pathlib import Path
# Add repo root (…\echomimic_v2) to PYTHONPATH so "src" is importable
REPO_ROOT = Path(__file__).resolve().parents[1]
sys.path.insert(0, str(REPO_ROOT))
from src.utils.img_utils import save_video_from_cv2_list
import cv2
import numpy as np
import os
from src.models.dwpose.dwpose_detector import dwpose_detector as dwprocessor
from src.models.dwpose.util import draw_pose
import decord
from moviepy.editor import AudioFileClip, VideoFileClip
from multiprocessing.pool import ThreadPool
##################################
# Make all paths in this script relative to the script folder (…\EMTD_dataset)
BASE = Path(__file__).resolve().parent
base_dir = str(BASE) + os.sep # replaces your previous base_dir="./"
tasks = ["temp"]
process_num = 800 # 1266
start = 0
end = process_num + start
#################################
MAX_SIZE = 768
def sanitize_for_ffmpeg(path):
"""If the basename begins with '-', rename it to avoid ffmpeg treating it as an option."""
d, name = os.path.split(path)
if name.startswith('-'):
safe = 'v_' + name
new_path = os.path.join(d, safe)
if not os.path.exists(new_path):
os.rename(path, new_path)
return new_path
return path
def convert_fps(src_path, tgt_path, tgt_fps=24, tgt_sr=16000):
os.makedirs(os.path.dirname(tgt_path), exist_ok=True)
with VideoFileClip(src_path) as clip:
new_clip = clip.set_fps(tgt_fps)
if tgt_sr is not None and clip.audio is not None:
new_clip = new_clip.set_audio(clip.audio.set_fps(tgt_sr))
temp_audio = os.path.join(os.path.dirname(tgt_path), "__tmp_audio.m4a")
new_clip.write_videofile(
tgt_path,
codec="libx264",
audio_codec="aac",
temp_audiofile=temp_audio, # <- safe temp file
remove_temp=True
)
def get_video_pose(
video_path: str,
sample_stride: int = 1,
max_frame=None):
# read input video
vr = decord.VideoReader(video_path, ctx=decord.cpu(0))
sample_stride *= max(1, int(vr.get_avg_fps() / 24))
frames = vr.get_batch(list(range(0, len(vr), sample_stride))).asnumpy()
if max_frame is not None:
frames = frames[0:max_frame, :, :]
height, width, _ = frames[0].shape
# detected_poses = [dwprocessor(frm) for frm in tqdm(frames, desc="DWPose")]
detected_poses = [dwprocessor(frm) for frm in frames]
dwprocessor.release_memory()
return detected_poses, height, width, frames
def resize_and_pad(img, max_size):
img_new = np.zeros((max_size, max_size, 3)).astype('uint8')
imh, imw = img.shape[0], img.shape[1]
half = max_size // 2
if imh > imw:
imh_new = max_size
imw_new = int(round(imw / imh * imh_new))
half_w = imw_new // 2
rb, re = 0, max_size
cb = half - half_w
ce = cb + imw_new
else:
imw_new = max_size
imh_new = int(round(imh / imw * imw_new))
half_h = imh_new // 2
cb, ce = 0, max_size
rb = half - half_h
re = rb + imh_new
img_resize = cv2.resize(img, (imw_new, imh_new))
img_new[rb:re, cb:ce, :] = img_resize
return img_new
def resize_and_pad_param(imh, imw, max_size):
half = max_size // 2
if imh > imw:
imh_new = max_size
imw_new = int(round(imw / imh * imh_new))
half_w = imw_new // 2
rb, re = 0, max_size
cb = half - half_w
ce = cb + imw_new
else:
imw_new = max_size
imh_new = int(round(imh / imw * imw_new))
imh_new = max_size
half_h = imh_new // 2
cb, ce = 0, max_size
rb = half - half_h
re = rb + imh_new
return imh_new, imw_new, rb, re, cb, ce
def get_pose_params(detected_poses, max_size, height, width):
print('get_pose_params...')
# pose rescale
w_min_all, w_max_all, h_min_all, h_max_all = [], [], [], []
mid_all = []
for num, detected_pose in enumerate(detected_poses):
detected_poses[num]['num'] = num
candidate_body = detected_pose['bodies']['candidate']
score_body = detected_pose['bodies']['score']
candidate_face = detected_pose['faces']
score_face = detected_pose['faces_score']
candidate_hand = detected_pose['hands']
score_hand = detected_pose['hands_score']
# 选取置信度最高的face
if candidate_face.shape[0] > 1:
index = 0
candidate_face = candidate_face[index]
score_face = score_face[index]
detected_poses[num]['faces'] = candidate_face.reshape(1, candidate_face.shape[0], candidate_face.shape[1])
detected_poses[num]['faces_score'] = score_face.reshape(1, score_face.shape[0])
else:
candidate_face = candidate_face[0]
score_face = score_face[0]
# 选取置信度最高的body
if score_body.shape[0] > 1:
tmp_score = []
for k in range(0, score_body.shape[0]):
tmp_score.append(score_body[k].mean())
index = np.argmax(tmp_score)
candidate_body = candidate_body[index * 18:(index + 1) * 18, :]
score_body = score_body[index]
score_hand = score_hand[(index * 2):(index * 2 + 2), :]
candidate_hand = candidate_hand[(index * 2):(index * 2 + 2), :, :]
else:
score_body = score_body[0]
all_pose = np.concatenate((candidate_body, candidate_face))
all_score = np.concatenate((score_body, score_face))
all_pose = all_pose[all_score > 0.8]
body_pose = np.concatenate((candidate_body,))
mid_ = body_pose[1, 0]
face_pose = candidate_face
hand_pose = candidate_hand
h_min, h_max = np.min(face_pose[:, 1]), np.max(body_pose[:7, 1])
h_ = h_max - h_min
mid_w = mid_
w_min = mid_w - h_ // 2
w_max = mid_w + h_ // 2
w_min_all.append(w_min)
w_max_all.append(w_max)
h_min_all.append(h_min)
h_max_all.append(h_max)
mid_all.append(mid_w)
w_min = np.min(w_min_all)
w_max = np.max(w_max_all)
h_min = np.min(h_min_all)
h_max = np.max(h_max_all)
mid = np.mean(mid_all)
print(mid)
margin_ratio = 0.25
h_margin = (h_max - h_min) * margin_ratio
h_min = max(h_min - h_margin * 0.65, 0)
h_max = min(h_max + h_margin * 0.5, 1)
h_new = h_max - h_min
h_min_real = int(h_min * height)
h_max_real = int(h_max * height)
mid_real = int(mid * width)
height_new = h_max_real - h_min_real + 1
width_new = height_new
w_min_real = mid_real - height_new // 2
w_max_real = w_min_real + width_new
w_min = w_min_real / width
w_max = w_max_real / width
print(width_new, height_new)
imh_new, imw_new, rb, re, cb, ce = resize_and_pad_param(height_new, width_new, max_size)
res = {'draw_pose_params': [imh_new, imw_new, rb, re, cb, ce],
'pose_params': [w_min, w_max, h_min, h_max],
'video_params': [h_min_real, h_max_real, w_min_real, w_max_real],
}
return res
def save_pose_params_item(input_items):
detected_pose, pose_params, draw_pose_params, save_dir = input_items
w_min, w_max, h_min, h_max = pose_params
num = detected_pose['num']
candidate_body = detected_pose['bodies']['candidate']
candidate_face = detected_pose['faces'][0]
candidate_hand = detected_pose['hands']
candidate_body[:, 0] = (candidate_body[:, 0] - w_min) / (w_max - w_min)
candidate_body[:, 1] = (candidate_body[:, 1] - h_min) / (h_max - h_min)
candidate_face[:, 0] = (candidate_face[:, 0] - w_min) / (w_max - w_min)
candidate_face[:, 1] = (candidate_face[:, 1] - h_min) / (h_max - h_min)
candidate_hand[:, :, 0] = (candidate_hand[:, :, 0] - w_min) / (w_max - w_min)
candidate_hand[:, :, 1] = (candidate_hand[:, :, 1] - h_min) / (h_max - h_min)
detected_pose['bodies']['candidate'] = candidate_body
detected_pose['faces'] = candidate_face.reshape(1, candidate_face.shape[0], candidate_face.shape[1])
detected_pose['hands'] = candidate_hand
detected_pose['draw_pose_params'] = draw_pose_params
np.save(save_dir + '/' + str(num) + '.npy', detected_pose)
def save_pose_params(detected_poses, pose_params, draw_pose_params, ori_video_path):
# e.g. EMTD_dataset/image_audio_features/pose/<video_stem>/
stem = os.path.splitext(os.path.basename(ori_video_path))[0]
save_dir = os.path.join(base_dir, "image_audio_features", "pose", stem)
os.makedirs(save_dir, exist_ok=True)
input_list = []
for i, detected_pose in enumerate(detected_poses):
input_list.append([detected_pose, pose_params, draw_pose_params, save_dir])
pool = ThreadPool(8)
pool.map(save_pose_params_item, input_list)
pool.close()
pool.join()
def save_processed_video(ori_frames, video_params, ori_video_path, max_size):
# e.g. EMTD_dataset/processed/video/<video_basename>
save_dir = os.path.join(base_dir, "processed", "video")
os.makedirs(save_dir, exist_ok=True)
save_path = os.path.join(save_dir, os.path.basename(ori_video_path))
h_min_real, h_max_real, w_min_real, w_max_real = video_params
video_frame_crop = []
for img in ori_frames:
img = img[h_min_real:h_max_real, w_min_real:w_max_real, :]
img = resize_and_pad(img, max_size=max_size)
video_frame_crop.append(img)
save_video_from_cv2_list(video_frame_crop, save_path, fps=24.0, rgb2bgr=True)
return video_frame_crop
def save_audio(ori_video_path, sub_task):
# read audio from the 24-fps video we just wrote
converted_path = ori_video_path.replace(sub_task, sub_task + "_24fps")
out_dir = os.path.join(base_dir, "processed", "audio")
os.makedirs(out_dir, exist_ok=True)
stem, _ = os.path.splitext(os.path.basename(ori_video_path)) # <- drop ".mp4"
# avoid leading '-' just like elsewhere
if stem.startswith('-'):
stem = 'v_' + stem
out_path = os.path.join(out_dir, f"{stem}.wav")
# write 16 kHz wav
with AudioFileClip(converted_path) as audio_clip:
audio_clip.write_audiofile(out_path, fps=16000)
def draw_pose_video(pose_params_path, save_path, max_size, ori_frames=None):
pose_files = os.listdir(pose_params_path)
# 生成Pose图cd pro
output_pose_img = []
for i in range(0, len(pose_files)):
pose_params_path_tmp = pose_params_path + '/' + str(i) + '.npy'
detected_pose = np.load(pose_params_path_tmp, allow_pickle=True).tolist()
imh_new, imw_new, rb, re, cb, ce = detected_pose['draw_pose_params']
im = draw_pose(detected_pose, imh_new, imw_new, ref_w=800)
im = np.transpose(np.array(im), (1, 2, 0))
img_new = np.zeros((max_size, max_size, 3)).astype('uint8')
img_new[rb:re, cb:ce, :] = im
if ori_frames is not None:
img_new = img_new * 0.6 + ori_frames[i] * 0.4
img_new = img_new.astype('uint8')
output_pose_img.append(img_new)
output_pose_img = np.stack(output_pose_img)
save_video_from_cv2_list(output_pose_img, save_path, fps=24.0, rgb2bgr=True)
print('save to ' + save_path)
if __name__ == '__main__':
visualization = False
for sub_task in tasks:
in_dir = os.path.join(base_dir, sub_task)
os.makedirs(in_dir, exist_ok=True) # just in case
ori_list = os.listdir(in_dir)[start:end]
# only take video files
mp4_list = [f for f in ori_list if f.lower().endswith((".mp4", ".mov", ".mkv", ".webm"))]
# where we write the 24fps conversions
new_dir = os.path.join(base_dir, sub_task + "_24fps")
os.makedirs(new_dir, exist_ok=True)
index = 1
for i, mp4_file in enumerate(mp4_list):
ori_video_path = os.path.join(in_dir, mp4_file)
if mp4_file.lower().endswith((".mp4", ".mov", ".mkv", ".webm")):
try:
# inside the for-loop, before convert_fps(...)
ori_video_path = sanitize_for_ffmpeg(ori_video_path)
tgt_name = os.path.splitext(os.path.basename(ori_video_path))[0] + ".mp4"
if tgt_name.startswith('-'):
tgt_name = 'v_' + tgt_name
ori_video_path_new = os.path.join(new_dir, tgt_name)
convert_fps(ori_video_path, ori_video_path_new)
print([index + start, ori_video_path, start, end])
# extract pose
detected_poses, height, width, ori_frames = get_video_pose(ori_video_path_new, max_frame=None)
print(height, width)
# pose parameters
res_params = get_pose_params(detected_poses, MAX_SIZE, height, width)
# save pose params
save_pose_params(detected_poses, res_params['pose_params'], res_params['draw_pose_params'],
ori_video_path)
# save cropped + padded video
video_frame_crop = save_processed_video(ori_frames, res_params['video_params'], ori_video_path,
MAX_SIZE)
# save audio
save_audio(ori_video_path, sub_task)
index += 1
if visualization:
pose_params_path = os.path.join(base_dir, "image_audio_features", "pose",
os.path.splitext(os.path.basename(ori_video_path))[0])
save_path = os.path.join("./vis_pose_results", os.path.basename(ori_video_path))
draw_pose_video(pose_params_path, save_path, max_size=MAX_SIZE, ori_frames=video_frame_crop)
except Exception as e:
print(["extract crash!", index + start, ori_video_path, start, end, str(e)])
continue
print(["All Finished", sub_task, start, end])
Besides, you also need to setmodel_det and model_pose in the src/models/dwpose/dwpose_detector .
import os
from pathlib import Path
import numpy as np
import torch
from .wholebody import Wholebody
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
device = "cuda" if torch.cuda.is_available() else "cpu"
# --- Resolve weights relative to this file ---
REPO_ROOT = Path(__file__).resolve().parents[3] # .../echomimic_v2
WEIGHTS_DIR = REPO_ROOT / "pretrained_weights" / "DWPose"
DET_ONNX = os.environ.get("YOLOX_ONNX", str(WEIGHTS_DIR / "yolox_l.onnx"))
POSE_ONNX = os.environ.get("DWPOSE_ONNX", str(WEIGHTS_DIR / "dw-ll_ucoco_384.onnx"))
class DWposeDetector:
"""
A pose detect method for image-like data.
Parameters:
model_det: (str) serialized ONNX format model path,
such as https://huggingface.co/yzd-v/DWPose/blob/main/yolox_l.onnx
model_pose: (str) serialized ONNX format model path,
such as https://huggingface.co/yzd-v/DWPose/blob/main/dw-ll_ucoco_384.onnx
device: (str) 'cpu' or 'cuda:{device_id}'
"""
def __init__(self, model_det, model_pose, device='cuda'):
self.args = model_det, model_pose, device
def release_memory(self):
if hasattr(self, 'pose_estimation'):
del self.pose_estimation
import gc;
gc.collect()
def __call__(self, oriImg):
if not hasattr(self, 'pose_estimation'):
self.pose_estimation = Wholebody(*self.args)
oriImg = oriImg.copy()
H, W, C = oriImg.shape
with torch.no_grad():
candidate, score = self.pose_estimation(oriImg)
nums, _, locs = candidate.shape
candidate[..., 0] /= float(W)
candidate[..., 1] /= float(H)
body = candidate[:, :18].copy()
body = body.reshape(nums * 18, locs)
subset = score[:, :18].copy()
for i in range(len(subset)):
for j in range(len(subset[i])):
if subset[i][j] > 0.3:
subset[i][j] = int(18 * i + j)
else:
subset[i][j] = -1
faces = candidate[:, 24:92]
hands = candidate[:, 92:113]
hands = np.vstack([hands, candidate[:, 113:]])
faces_score = score[:, 24:92]
hands_score = np.vstack([score[:, 92:113], score[:, 113:]])
bodies = dict(candidate=body, subset=subset, score=score[:, :18])
pose = dict(bodies=bodies, hands=hands, hands_score=hands_score, faces=faces, faces_score=faces_score)
return pose
dwpose_detector = DWposeDetector(
model_det=DET_ONNX,
model_pose=POSE_ONNX,
device=device)
print("dwpose_detector init ok", device, "\n det:", DET_ONNX, "\n pose:", POSE_ONNX)
Then run the script:
python preprocess.py
This script takes every video in ori_video_dir_segs and turns each one into:
- a clean, square, 24-fps video clip (center-cropped around the person):
./processed/video/ - a 16kHZ WAV audio file for that clip:
./processed/audio/ - pose data (NPY files):
./image_audio_features/pose/<video_name>/
Finally, we have a dataset for halfbody human animation.
If you found this article helpful, please show your support by clicking the clap icon 👏 and following me 🙏. Thank you for taking the time to read it, and have a wonderful day!
References
- https://github.com/yt-dlp/yt-dlp
- https://github.com/he-yulong/echomimic_v2/tree/052c92d1a17bf200ce08662638454ac62ffce8c0